
Strawberry Jam: A quick hacking session with OpenAI's new model
An afternoon's work done in 7 seconds.

Yesterday, OpenAI released two new models, o1-preview and o1-mini, codenamed “Strawberry”. These models have been trained to spend time reasoning before responding. They work by first planning the steps necessary to solve a problem and then iteratively executing those steps — the output from each step feeds the input to the next.
In some sense, this is nothing new. People are taught to solve problems iteratively as soon as they enter school. And, we work with AI in the same way. Chatbots rely on collaborative, multistep reasoning. Each time the AI responds, we evaluate the response and figure out what’s next: are we done solving our problem or do we want to take another pass?
To date, a collaborative approach has been necessary to get the best results from AI. Large language models don’t do this type of reasoning naturally, so they need a little help from a friend.
Prior to OpenAI’s release, there have been some advances in reasoning. For example, chain of thought is a prompt engineering technique that encourages the AI to do the multistep thinking without us shepherding each step of the way. But, it suffers from the problem that everything is done in one pass — the LLM doesn’t have the opportunity to reconsider before responding.
OpenAI’s o1 models don’t have this limitation. As a result, they are more likely to correctly reason through complex problems and provide robust solutions. Let’s look at an example.
Using AI to develop a merchandizing strategy
I’m currently working with a healthcare company called Sesame. We recently launched a new medical weight loss offering and we want to make sure that site visitors are aware of the offering. Sesame has an extensive blog with highly ranked pages across a diverge range of medical conditions & topics like Best Medications and Treatment Options for Anger Management, What is Self-Care? Sustainable Tips for a Healthier You, and the highly searched Can a Belly Button Infection Kill You? 🙀.
We’d like to put a CTA for the weight loss program on relevant blog pages. But, which pages are relevant? There are hundreds to go through.
Crazy idea… we can write a script to crawl through all of the blog pages and have OpenAI determine if the page is relevant to weight loss. In a few hours of coding, we’d accomplish what would have taken days of manual work.
But, we could go a step further. Can we get ChatGPT to write the script for us?
Attempt #1 — Code generation without Strawberry (ChatGPT 4o mini)
I need ChatGPT to do quite a bit of work:
Crawl the Sesame /blog page to find blog articles
Evaluate each blog page to determine if that page is relevant to weight loss and why readers of that page might be interested in weight loss
Output the results to a CSV file
Make sure we don’t get rate limited by the OpenAI API or Sesame’s servers
I’ll need to have a good prompt that is specific and lays out all the requirements:
I work with a company called Sesame. We have a new product that enables people to lose weight using GLP-1 drugs like semaglutide, Wegovy, and Zepbound. I want to place a cross-sell module on all blog pages that discuss topics relevant to someone looking to lose weight. Build a crawler that will crawl https://sesamecare.com/blog and all blog posts (subpages of that URL). For each page, use the OpenAI API to determine if that page is relevant to weight loss and why readers of that page might be interested in weight loss. Output a .CSV file with three columns: the URL for the blog page, a true/false column indicating if that page is relevant to weight loss, and a 1-2 sentence description of why that page is relevant to people seeking weight loss.
Let’s see how it did:
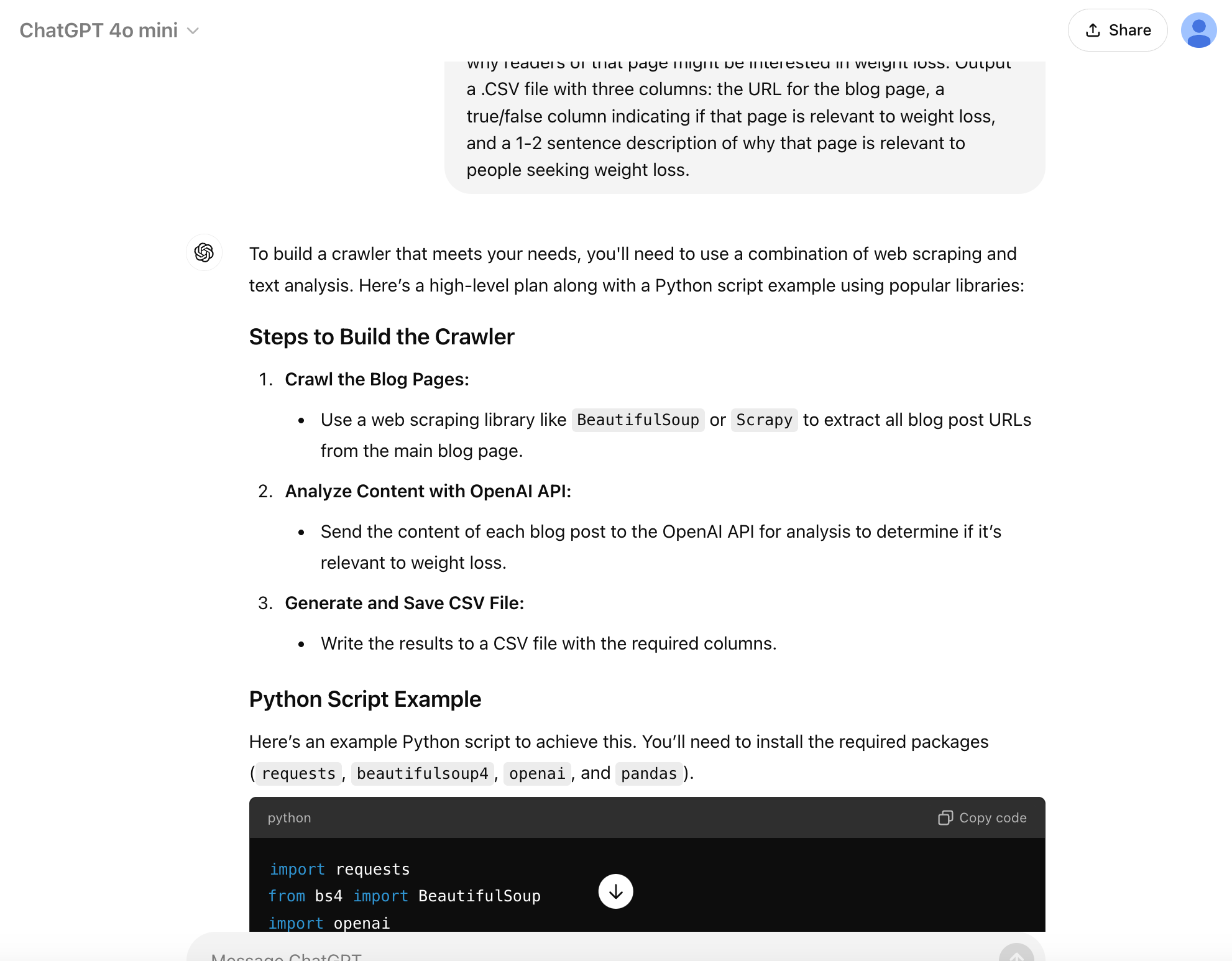
The AI “transformed” my prompt by adding a chain of thought plan with the three steps I implied, but didn’t explicitly articulate in the prompt:
Crawl the Blog Pages
Analyze Content with the OpenAI API
Generate and Save CSV File
It also generated a complete script which you can check out with the chat link: Sesame Blog Crawler - 4o mini.
As is typical with non-reasoning models, we have a starting point, but significant iteration is required to get to a good end state. Here are some things to improve:
The code a rudimentary approach to analyzing content which is likely to be inaccurate. For some reason, it’s explicitly looking for the words “weight loss” in the results which is too narrow to work properly.
No error handling
No rate limiting on either OpenAI requests or requests to the Sesame site
Uses an old version of the OpenAI SDK
Attempt 2 — We’re jammin’ (ChatGPT o1-preview)
Let’s see what Strawberry can do. We’ll use the same prompt:
In this video, you can see both the initial generation and a refinement. After reviewing the code, I realized that I wanted to be able to test it on a small subset of URL’s so I asked ChatGPT to revise the code with that new requirement.
Here’s the reasoning o1-preview used to write the script:

The script is a significant improvement over the first try:
Clear instructions on what Python packages are required and how to run the script. Very useful for a non-programmer to get up to speed.
Robust logic for crawling that won’t get stuck in an infinite loop
Better text extraction from each blog page
Better use of the OpenAI API’s with a better prompt (although it’s still using the old OpenAI SDK)
A nice progress bar to track progress during the analysis (which can take several minutes to run)
Error handling and rate limiting
This code is almost flawless and can run with a minor change. Here are some of the results:
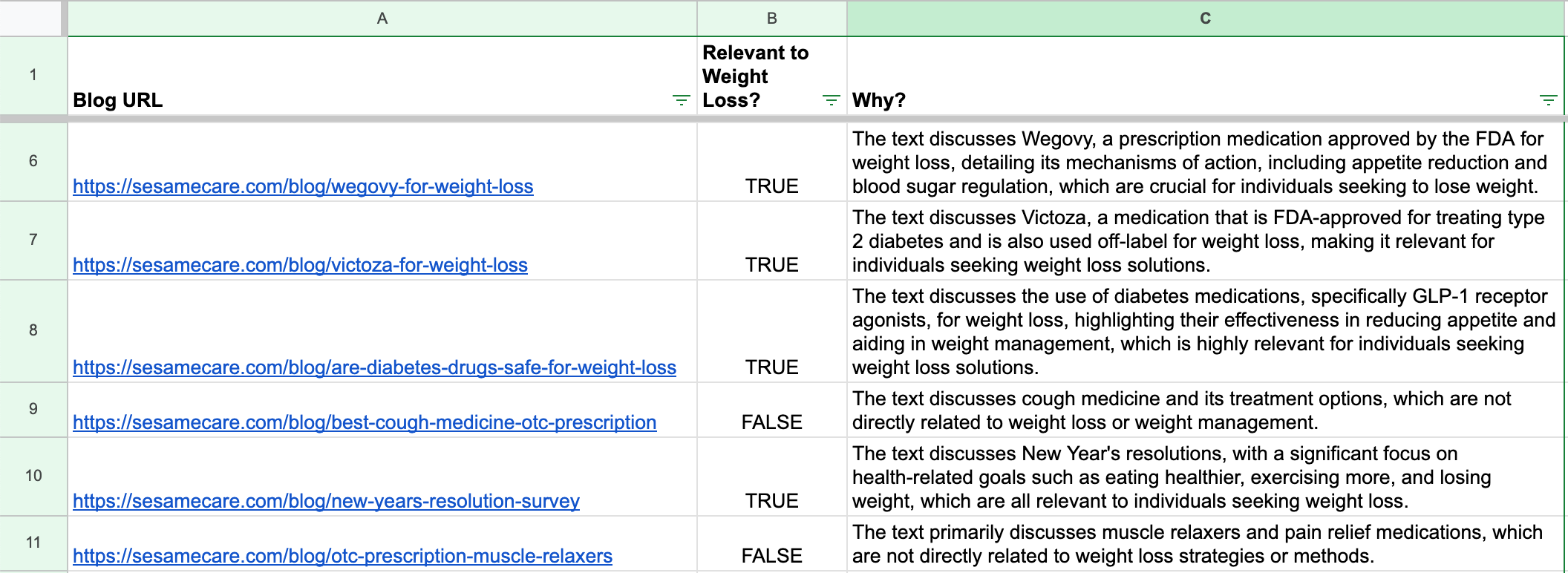
Ironically, the only problem with this code is the use of the OpenAI SDK. The code is written for an older version of the OpenAI SDK that will fail unless that older version is explicitly installed.
I got it working when I installed the older version of the SDK, but I really wanted it to work with the latest SDK. As you can see in the Sesame Blog Crawler - o1-preview chat, I tried to get it to update the code and even pointed it to the latest OpenAI SDK docs.
But, even OpenAI is not immune to the limits of LLMs. The model underlying o1-preview was likely trained before OpenAI’s new SDK came out, and so it’s using the old approach even when prompted with the updated docs.
The OpenAI SDK is changing fast, and the OpenAI models just can’t keep up.
The frontier just advanced — again 🥱
In reality, it took me about an hour to go from using o1-preview the first time to having a fully working, AI-enabled web crawler. But, had it not been for the OpenAI SDK issue, I would have had a working program in minutes.
In a couple of years, a process that took days got shrunk to hours and now minutes.
It’s crazy to think that these advances are coming so fast that they almost feel routine. The multimodal capabilities of OpenAI are jaw dropping, and yet they seem like old news!
Don’t sleep on this one… I think you’ll be surprised at what’s possible.
What do you want to create with Strawberry?
NOTE: This did require some coding skill to get working, but I’m not a Python programmer. ChatGPT and Github Copilot taught me everything I know.

Hi Ravi, great post! I’m curious to know how I can leverage OpenAI, particularly using a chain of thought approach, to help with business cases. By business cases, I mean I'm working on planning several cases and would like to understand how OpenAI can assist in this process. Any insights or suggestions?