
How to stop tokenmaxxing and cut AI spend 10x
Three fixes to reduce token burn and improve ROI.

Earlier this year two trends were woven together to coin an unlikely new term. In March, Jensen Huang said he would be alarmed if an Nvidia engineer didn’t consume at least half their salaries worth of tokens in a year. This sent shudders through people on both sides of the AI hype. AI maximalists, having proudly shelled out $200 a month to unleash the hounds now felt hopelessly behind. CFOs balked at the idea of a 50% increase to their R&D budget when costs were supposed to be going way down.
Around the same time, the manosphere’s obsession with male beauty made looksmaxxing the word of the day.
Thus, “tokenmaxxing” was born — and it’s become the AI skeptic’s shorthand for “I told you so.” The party line: productivity gains aren’t showing up in the macro numbers, yet companies are burning millions on AI spend. Business Insider reported that Uber blew through its entire annual AI budget in just four months, while Axios cited an AI consultant whose client allegedly spent half a billion dollars in a single month after failing to put limits on employee Claude usage. The details of that $500 million anecdote are hard to independently verify, but the point landed because it captured a fear that suddenly felt plausible: AI adoption had become a blank check, and the invoice is arriving before the ROI.
I don’t think tokenmaxxing is a sign of AI’s demise - it’s the result of very real growing pains. It’s the burst of spastic energy kids throw into learning to walk.
Spend time around an AI-native product development team, and you’ll see significant productivity gains. But the prevailing approach to capturing those gains has been almost caveman-like — more AI good! — with little discipline around cost.
The good news: wasted token usage is a highly solvable problem. The catch is that the fixes go against the grain of AI “best practice.” Lets look at 3 very effective ways to burn fewer tokens — and get better results at the same time. Taken together, cost savings of 5x-10x are very achievable.
1. Stop defaulting to the most capable model.
This fix is obvious — and yet it gets ignored, because the frontier model feels like the safe choice. Writing code, reviewing a contract, summarizing research, drafting a memo for an executive — the instinct is to reach for the most powerful model on the menu and crank reasoning to the top. Nobody wants to be the person who saved three cents and shipped the wrong answer.
That instinct is precisely how tokenmaxxing gets expensive.
A frontier reasoning model bills you twice. First, every token costs more, coming and going. Second, the model is built to think before it answers, and that thinking isn’t free — the hidden reasoning never appears in the response, but it’s billed as output all the same.
With a reasoning model, you aren’t just paying for the answer. You’re paying for the deliberation.
Providers have noticed. Anthropic now lets Claude decide how much to think based on the request; OpenAI exposes reasoning-effort controls. Useful — but adaptive reasoning trims the meter, it doesn’t change the rate. Call the premium model and it might think less, but those tokens are still expensive. The real savings come from seeing what a task actually needs and routing it to the appropriate model on purpose.
And the gap is enormous. On OpenAI’s pricing, GPT-5.5 runs $5 per million input tokens and $30 per million output; GPT-5.4 mini lists at $0.75 and $4.50 — more than 6x cheaper on both, with nano cheaper still. Anthropic tiers the same way: Haiku at $1 and $5, well below Sonnet and Opus.
The obvious objection: cheaper models are dumber. That’s increasingly out of date. These days, mid-tier often means last generation’s frontier.
Take Sonnet 4.5. When it launched in September 2025, Anthropic put it at the front of the pack for coding and pitched it as their strongest model yet for complex agent work. Two months later, Opus 4.5 moved the frontier again — but the comparison is the tell: at medium effort, Opus 4.5 matched Sonnet 4.5’s best SWE-bench Verified score using 76% fewer output tokens, and at full effort beat it by 4.3 points while still using 48% fewer. The “less capable” model isn’t weak. It’s last quarter’s flagship, now cheap.
So the policy isn’t “never touch the frontier model.” It’s this: the premium model is an escalation path, not a default.
Extraction, classification, summarization, formatting, first-pass drafts, routing, data cleanup, most internal productivity work — a small or mid-tier model is plenty. Save the frontier model for ambiguous strategy, hard coding, complex agents, legal or medical reasoning, anything where being wrong is expensive. Even then, use the lowest reasoning level that reliably gets there.
This reshapes how agents get built. The naive agent calls the strongest model at every step. The better agent runs a hierarchy: a frontier model draws up the plan, a mid-tier model executes the routine steps, a small model classifies, extracts, and validates. You’re not minimizing intelligence. You’re spending it where it has leverage.
And cost isn’t even the whole case. Overshooting the capability mark slows you down — and latency is what decides whether employees keep using an internal tool and whether customers stay in a product at all. It also adds variance: deep reasoning explores, wanders, overcomplicates simple requests, and answers a little differently each run. For plenty of workflows, a predictable answer beats a marginally smarter one.
Tokenmaxxing treats capability like an all-you-can-eat buffet — biggest model, max reasoning, more is always better. The fix is to treat it like what it actually is: a scarce resource you spend where it pays off.
2. Use skills sparingly.
The second fix for tokenmaxxing is counterintuitive: use fewer skills.
That sounds wrong at first, because skills solve one of the most important problems in AI systems: reusable context engineering. A good skill packages instructions, examples, workflows, formatting rules, domain knowledge, and tool-use patterns so the model can reliably perform a task the same way every time. Used well, skills save time. They make output predictable. They turn one person’s hard-won process into something a whole team can run.
That matters because context engineering is one of the highest-leverage ways to improve AI output. The model isn’t answering your last sentence — it’s answering everything in front of it: the system prompt, the history, the tool descriptions, the files, the policies, every loaded skill.
The problem is that many people treat skills like apps on a phone — install them and forget them. But a skill isn’t just a capability; a skill is context. Installed skills stay dormant until the model decides one is relevant and loads it — you don’t choose when that happens. Once loaded, a skill sits in the context window for the rest of the session, elbowing the system prompt, the conversation, and the actual question for room.
The promise is seductive — skills should snap together like LEGO blocks. Load a writing skill, a research skill, a citations skill, a brand-voice skill, a SEO skill, a Substack publishing skill, and maybe a “make it viral” skill, then ask the model to produce a finished article. In theory, this sounds like giving the model a team of specialists. In practice, it often means dumping a pile of partially relevant instructions into the context window and hoping the model sorts them out.
That can create three failures at once.
First, it burns tokens. If the user asks for a 300-word edit but the system loads thousands of tokens of skill instructions, most of the cost is not the user’s request or the model’s answer. It is the overhead.
Second, it slows the system down. The model has more context to process before it can respond, more possible tools to consider, and more irrelevant instructions to filter out.
Third, it can make the answer worse. Large context windows are powerful, but they are not magic. Agents can lose focus or become confused as context grows, a failure mode often described as context rot. The more irrelevant context you load, the more you risk crowding out the signal the model actually needs.
The lesson isn’t that skills are bad — it’s that context needs to be shaped to the task, not overloaded with the kitchen sink. Context should be defined just in time, not just in case.
Context should be defined just in time, not just in case.
Good skills are deliberately scoped, concise, tested, and clearly triggered. Bad skills behave like giant always-on system prompts: every edge case, every preference, every workflow, written once and never audited. Over time, they become a hidden tax on every request — especially when plucked from a free skill directory.
So before adding a skill, ask: What workflow does this unlock? What gets loaded upfront? Can the detail be deferred? And most importantly: read the skill. If you don’t understand what each line is meant to do, you cannot know whether it’s helping or hurting — but the meter is running, either way.
3. Don’t use AI as a general purpose computer.
The third fix for tokenmaxxing is the most important: don’t use AI as a general-purpose computer.
For most of software’s history, there was one way to build systems: you wrote the rules. An input came in, a chain of instructions (the code) transformed it, an output came out. That simple loop — input, rules, output — is what every spreadsheet, every payment system, every video game running at 60 frames per second is doing under the hood. The defining innovations of the last fifty years are almost all variations on the same idea: more rules, executed faster, on more inputs.
But computation has a hard constraint: you can only build what you can express. You can write the rules to check whether a GPS coordinate falls inside a national park. You cannot write the rules to identify a bird in a photo. The features of “bird” — shape, color, posture, angle, lighting — sprawl across too many dimensions to capture in code. Try it. You’ll fail.
That’s where learning systems come in. Instead of starting with the rules, you start with the data. A million photos labeled “bird” or “not bird” go into a model, and the model finds its own rules. The output looks like magic, because the rules were never written down. They emerged from the training process.
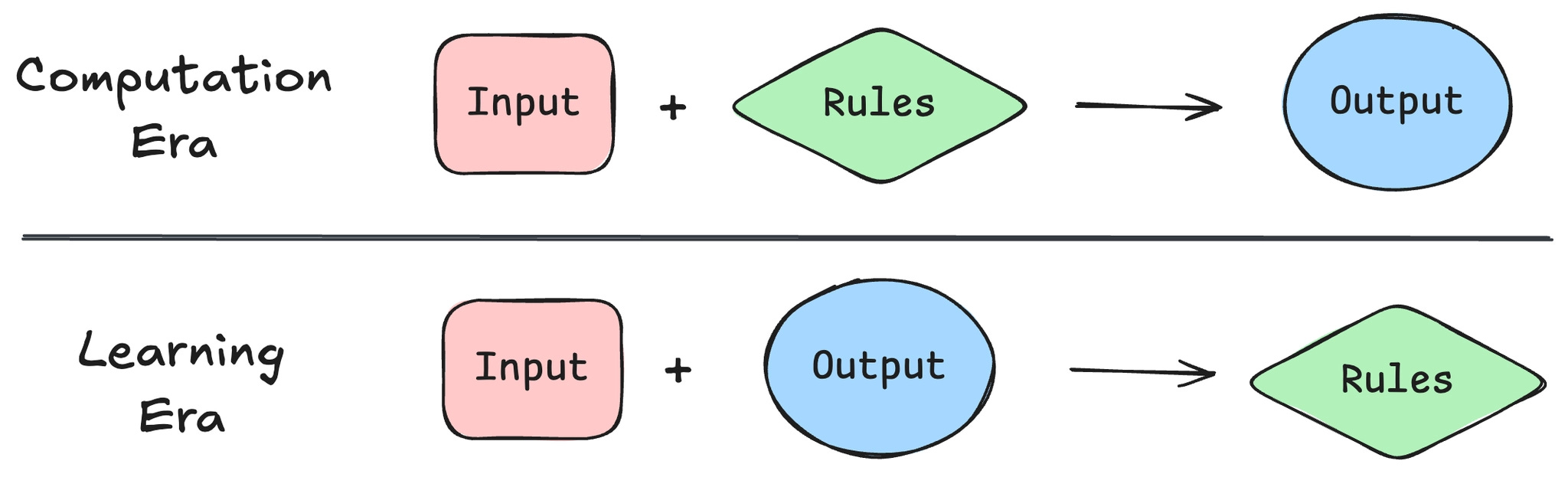
Today every product team has both paradigms on the table:
Start with the rules. Computational systems. Deterministic, precise, brittle.
Start with the training data. Learning systems. Flexible, probabilistic, fuzzy.
(Today, “start with the training data” typically means “use a model someone else has already trained.”)
These two paradigms are not interchangeable, and their strengths and weaknesses are often diametrically opposed — what makes computation great is exactly what makes learning weak, and vice versa. I wrote about this contrast in more detail in Shifting to an AI mindset, but the short version: computation is for problems with rules. Learning is for problems where humans can recognize the answer but cannot explain it.
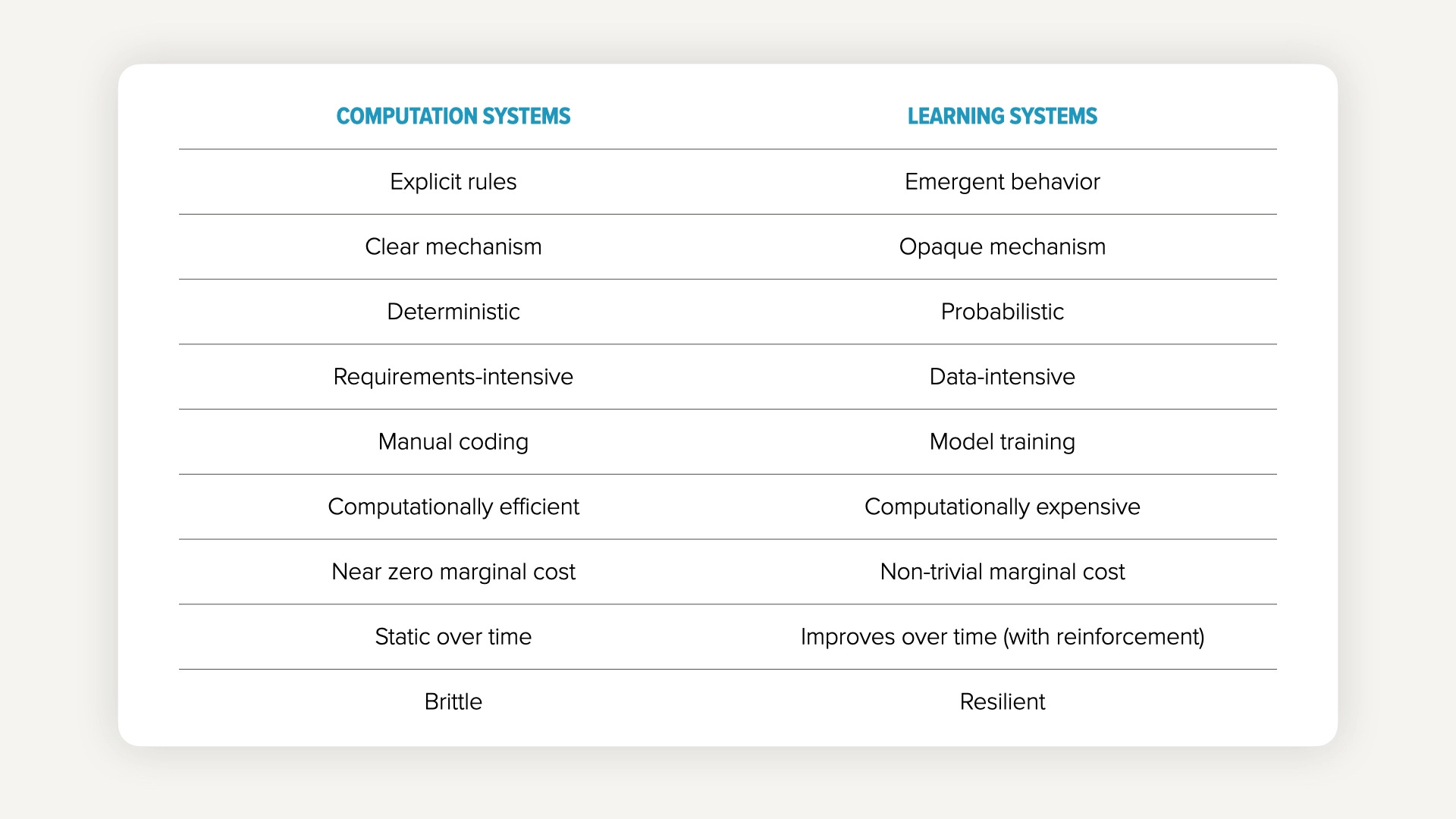
The trouble starts when we forget the distinction.
LLMs are seductive because they feel like computers. You can ask one to add numbers, sort a list, classify an email, return strict JSON in an exact schema, run a 200-step workflow. It will usually do it. So people start treating the LLM as a general-purpose computer — a place where any logic can live, written in English, sitting in the context window.
That’s where tokenmaxxing accelerates.
The context window starts to look like code. “If the user mentions pricing, do X. If the field is empty, ask Y. If the date is in the past, return Z. Unless they’re a premium customer, in which case…” Every if-then we used to write in code we now write in English, shove into a prompt, and hope.
But a context window is not a codebase. A codebase is precise — millions of lines can sit in a repo, and at runtime exactly the right function fires, exactly when needed, with deterministic results. A context window is meaningful different. As we saw in the last section, it’s a shared resource the model pulls from with high variability and low precision. Add more rules and the probability that the right one fires at the right moment doesn’t go up. It goes down.
The fix is to recognize which kind of problem you’re solving and route it to the right tool.
Learning problems are things humans solve through pattern recognition — judging tone, summarizing a meeting, drafting prose, classifying intent, reading a messy table. Use the model.
Computational problems are things with rules — math, lookups, sorting, validation, deterministic workflows, anything where the same input must always produce the same output. Use code.
Sometimes the model recognizes a computational problem and writes code to solve it. Early ChatGPT famously could not count the R’s in “strawberry” — until newer versions started generating Python on the fly to answer. That’s the right instinct, and it’s worth knowing the model has it. But you can’t depend on it.
The disciplined approach is to combine the two on purpose: build small, deterministic computational tools and expose them to the model. The model decides when to call them; the tool returns a clean result. This pattern — known as “tool use” or “function calling” — does three things at once. It shrinks the context window. It sharpens reliability. And it cuts cost, often dramatically, because the heavy lifting moves out of the LLM and into code that runs for fractions of a cent.
For many problems — maybe most — a computational approach will be more predictable, faster, and cheaper than asking the model to do it in English. That doesn’t mean AI is overrated. It means AI is one tool inside a system, not the whole system.
The tokenmaxxing instinct is to treat the LLM as the computer. The fix is to remember it isn’t. AI won’t eat software — it will use software to do the things outside its domain.
Three fixes, but really one principle: match the capability to the task:
Use the smallest model that does the job.
Load only the context the work actually needs.
Send rule-based problems to code, not to a model imitating code in English.
Tokenmaxxing isn’t a verdict on AI. It’s a growing pain. New carpenters waste a lot of wood. New artists waste a lot of paint. With mastery comes efficiency.
The teams that figure this out won’t go back to working the old way because their AI experiment failed. They’ll stop flailing and learn the ins and outs of their tools. They’ll craft with mastery and with intent.
Tokenmaxxing is what learning to walk looks like. Running is next.
Ravi,
Excellent analysis.
I’ve been arguing that the winning architecture for most enterprise AI systems will be a hybrid of deterministic and non-deterministic approaches. LLMs are incredible for discovery, ideation, ambiguity, and rapid prototyping, but many production workflows eventually benefit from being refactored into deterministic systems where possible. That improves cost, reliability, explainability, and scalability. Meaning use the speed of non-deterministic to get to the deterministic effectively.
In our product and AI labs since last year, we often followed a pattern:
• Used frontier models to rapidly explore, prototype, and discover solutions
• Identify where reasoning is actually required versus where deterministic logic, traditional ML, or conventional software can perform the task more efficiently. Also think through about what are plain vanilla tokens vs. thinking tokens. Bifurcate the branches. Even count the tokens used per total turns achieving the outcome.
• Re-architect the workflow accordingly.
Healthcare is a great example. Much of clinical decision-making ultimately maps to evidence-based rules, protocols, and structured logic. The challenge isn’t replacing everything with LLMs it’s understanding where language reasoning adds value and where it doesn’t.
In another use case it took me 47 versions via to optimize parallel API calling rather than sequential for a map /geo solution I was iterating on. The frontier models could not do it, whereas if I coded it - this would take 10 minutes. A lot of tokens and two hours wasted.
Your point on “skills” resonated. I’ve wondered whether we’re sometimes just relocating context-window complexity rather than reducing it. Hidden prompt bloat, excessive guardrails, and agent-to-agent chatter can create significant token overhead with diminishing returns, which are additional, yet similar topics that add to “token maxxing.” I still want to try dynamic inference calling at the time of the agent processing to both closed or open models to see how this performs.
We all know now a solution - it’s likely a tightly orchestrated system of specialized components, each with a “very” narrow responsibility, small context window, and clear evaluation criteria. But if its too narrow, does that not become a function call? That architecture tends to be more efficient, more reliable, and less prone to cascading hallucinations.
For PMs, the real “craft” is cradt systems to consistently reach 90–95%+ human-level performance through rigorous evals and iteration. Though, sometimes my mind gets numbed or bored by sub-optimal time in tweaking. Once that threshold is achieved, the hard work shifts to industrializing the solution governance, monitoring, reliability, and engineering inference at scale and in parallel.
Great perspective on the skills layer where at times they get called up. On another note, Anthropic did a great session on optimizing guardrails via evals late last week (one can Google the accompanying video). Workshop name: agent decomposition. https://github.com/anthropics/cwc-workshops and XVideo: https://x.com/0x_rody/status/2061019244595233135?s=20
I especially appreciate the piece you share about building skill libraries and how much context is dragged along when invoking them.